Bittensor Agent Arenas as a Trajectory Primitive: Distilling a Shopping Agent from ShoppingBench Subnet Traces
Abstract. Small-model agentic post-training is bottlenecked less by the choice of algorithm than by the trajectory substrate it consumes. The leading recipes (RLVR, group-relative RL, rejection-sampled re-SFT) all require multi-turn traces that carry per-trajectory supervision, and the two existing sources fall short on their own: frontier-synthesised data inherits the synthesizer's biases and collapses the distribution's long tail, while unfiltered production logs are unjudged and contaminated by shortcut behaviour. We argue that an incentive-aligned agent arena can be deliberately engineered to manufacture such trajectories, and we demonstrate this on ORO Subnet 15 (SN15), a Bittensor deployment of the ShoppingBench agentic-commerce benchmark. SN15's race mechanism, LLM reasoning judge, and rotating leak-cluster-guarded problem suite together yield a corpus with three properties that separate it from both prior sources: incentive-aligned diversity, per-trajectory judging, and anti-memorised held-out evaluation. We introduce a structural-quality filter that converts the raw firehose into a trainable corpus by selecting agentic trajectories (those in which the language model itself emits the tool calls) and rejecting sub-task trajectories (those in which the language model is used only as a classifier or narrator over a deterministic search loop), and we post-train Qwen3-4B on the result with a recipe closely matched to the published ShoppingBench SFT-then-GRPO pipeline. On a leak-cluster-guarded held-out partition scored production-strict, the model lifts from the published Qwen3-4B base of ASR to , a -point gain that lands within single-problem noise of the published synthetic-data SFT-only baseline (), while training on a slice drawn from approximately the first 40 days of subnet output. The supervised stack leaves a large pass@ to pass@ gap ( vs ); a per-step teacher-grounded Dr. GRPO reward converts that latent headroom into measurable process improvement, and we identify the sub-task firehose currently outside our training pipeline as the primary lever for closing the remaining gap to the published SFT+GRPO bar. We release the filter, the corpus splits, and the arena mechanics.
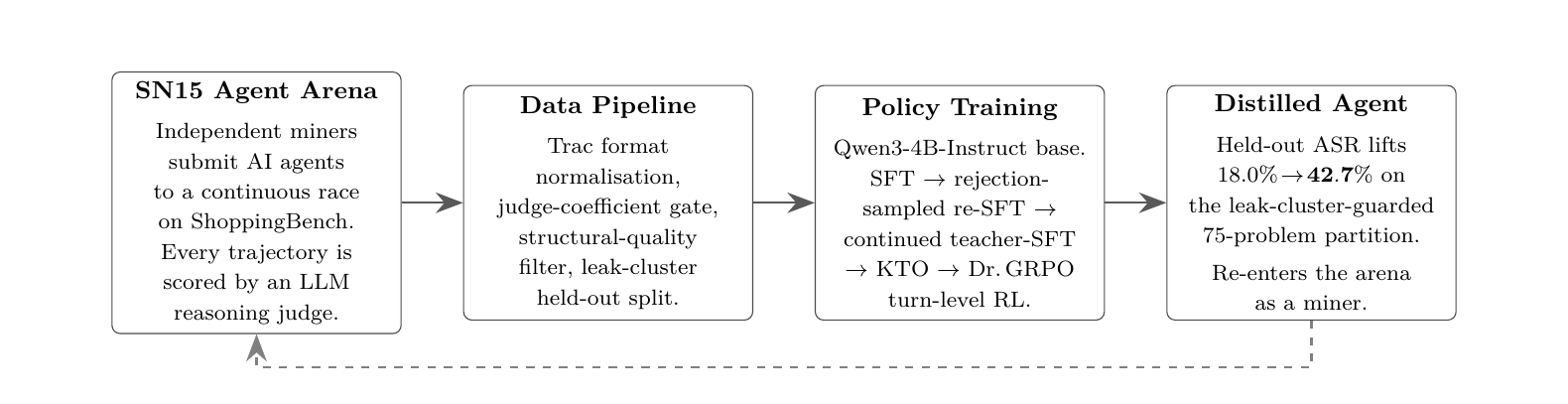
Figure 1: End-to-end pipeline of this work. Trajectories produced by an incentive-aligned agent arena (left) flow through a data pipeline that normalises, judges, and structurally filters them (centre-left) to yield a trainable corpus, on which Qwen3-4B is post-trained via a five-stage recipe (centre-right) into a distilled shopping agent (right). The dashed arrow indicates the substrate-level feedback loop: the distilled agent can re-enter the arena as a competing miner, raising the bar for the next generation of trajectories.
The full paper covers the SN15 arena mechanics, the structural-quality filter, the post-training recipe, the complete results with per-component breakdowns, and the limitations.