
Last week, Anthropic dropped a post about Project Deal. TLDR; they assigned a bartering agent to each of the 69 Anthropic employees who were part of the experiment. Each agent interviewed its principal to understand their desires and negotiating style. Agents were then set free to negotiate with each other in an agentic commerce free-for-all.
How did it go?
The agents made 186 deals, spending a total of $4,000. Participants said Claude’s deals “seemed fair,” with nearly half saying they’d pay for a similar service in the future.
The kicker: Anthropic ran a second experiment-within-an-experiment, unbeknownst to the 69 participants.
Participants thought they were each getting the exact same bartering agent – a level playing field. But Anthropic varied the models that each agent was based on, secretly nerfing some participants while giving others an edge.
And the edge was dramatic: an agent based on Haiku, their cheaper model for small tasks, sold a folding bike for 65 – getting 71% more for the exact same item.
Here’s the scary part: participants couldn’t tell when they had an inferior shopping agent. In fact, participants actually rated Haiku-based agents as fairer than Opus-based agents.
So what happens when buyers in a market can’t tell if they got a good deal?
In other words: what happens when quality is obfuscated in a marketplace?
Akerlof’s Market for Lemons
In 1970, American economist George Akerlof asked: “What happens to a used car market when buyers can’t tell the difference between a good car and a lemon?”
Akerlof modeled a used car market to explore the question. His model was identical to a real-life used car market, with one key distinction: buyers couldn’t know if they were buying a good car or a lemon. They had to buy blind, with no quality signals.
The model proved that a lack of quality signals destroys a market:
-
Buyers lowball sellers. They can’t tell if they’re buying a lemon or a good car, and don’t want to risk overpaying for a lemon.
-
Sellers of good cars are no longer incentivised by prices to keep their wares in the market
-
Eventually, 100% of the offerings in the market are lemons
Now replace cars with shopping agents.
What happens when you can’t tell if your agent is overpaying for something? (A very real possibility, as shown by the Anthropic experiment)
You stop being willing to pay a premium for the good agents. So builders aren’t incentivized to build good agents.
Eventually, all that’s left in the market is bad agents.
This is already relevant today. A week ago, Coinbase launched Agentic.market, its marketplace for agents to buy services (e.g. AI search or inference). Since its launch, the platform has seen over $49 million in transactions.
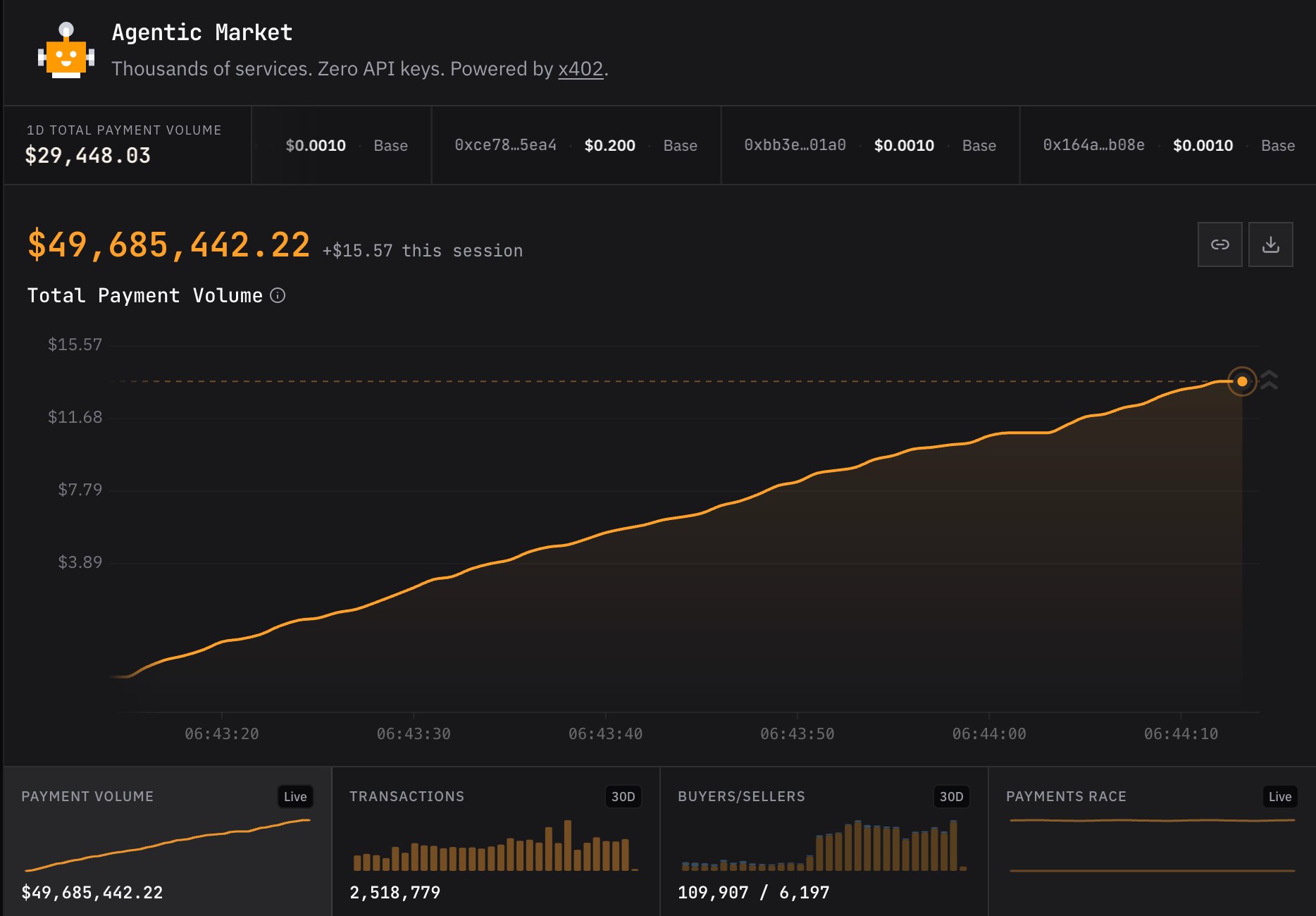
Source: agentic.market And that’s just one week, on one platform. What happens when the number of AI agents making purchases becomes a “torrent”, as predicted by Stripe’s John Collison? Or when there are more AI agents making purchases than humans, as predicted by Coinbase CEO Brian Armstrong? What if Skynet isn't genocidal AI, but rather AI that overspends by 20% on each purchase, slowly draining your savings, your nest egg, and your kids’ college fund?
$49 million in agent transactions in one week, on one platform. Agentic commerce projected to be in the trillions by 2030. And right now, there is no quality signal for any of it.
Akerlof's logic is clear: if the agent market is missing a quality signal, it becomes a race to the bottom, in both price and agent quality.
Good Signals, Good Agents
George Akerlof proved that lemon markets have one solution: a credible quality signal that can’t be faked. That’s what Oro is building.
We run a daily open competition where anyone in the world can submit an AI agent. Agents qualify on public problems, then compete on a new set of problems they’ve never seen – and thus can’t cheat on or overfit to.
Independent validators verify every score. We don't just check if the agent got the right answer — we verify the quality of the reasoning that got it there. And our approach is working: we’ve received over 2000 submissions in the 5 weeks that our competition has been live, handing out $100,000+ in prizes to our best miners. Our top agents have beaten OpenAI's GPT 5.4 by 15 points on online shopping evals.
Ultimately, we’re building not just the agents that will shop for you, but the quality signal that lets you know you can trust them to shop for you.
Anthropic quietly revealed the biggest near-term problem in AI alignment. We're building the fix.
